Intro
最近遇到了一个问题:一个基于Distilbert模型Fine-Tune过的模型在NPU上表现很差,推理平均时间远高于GPU,甚至于CPU拉不开差距。测试设备是Google Pixel 7Pro,搭载了Google自研TPU。网络上关于移动边缘侧推理性能的Issue很多,但是牵扯到NPU异构加速的Issue基本上很难有个清晰的解决方案,常见的情形是放弃NPU方案或者更换模型碰碰运气(淦我怎么老是在搞这些没有人搞的破活)。很遗憾在这里两个摆烂方案都不可行,好在一番东翻西找之后解决了问题,将解决方案记录在这里,也给可能有类似问题的后来者一个参考。
NNAPI
众所周知,随着设备端侧算力的不断加强和诸如隐私计算等政治正确要求的出现,越来越多的MLSys开始注重将Inference(甚至Training)迁移到设备侧。除传统的CPU推理外,越来越多的异构加速模块也开始加入战场,如GPU、DSP甚至厂商定制化的专用加速单元(他们有个好听的名字叫做神经网络运算单元NPU)。高度定制化的加速单元在针对性的模型和算子上可以达到非常高的性能,但想要让加速单元能较好的推理特定的DL模型需要额外的适配和测试工作(如高通NPU(在865之前叫做DSP)只能接受Int8的模型Tensor推理,而华为Kirin的NPU在Float32 Tensor上的性能最好,Google Tensor自研TPU的具体信息更是完全黑盒)。好消息是,面对如此百花齐放又千奇百怪的异构加速单元,Android系统引入了一层虚拟层来封装这些差异,称为(Neural Network API,NNAPI);坏消息是,NNAPI的版本必须随Android大版本一并更新(因此碎片化现状也不可避免),而且NNAPI本意是作为DL Framework(如TFLite MNN)等的一个计算后端来设计,因此API十分low-level,文档也过于简洁(见此),给开发者调试的过程带来了很多困难。

一个简单的模型推理的调用流程图如图所示,App通过加载ML Lib来运行模型,ML Lib(如TFLite)会视模型内算子的类型将模型分为几个子图,分配的原则是一方面每个子图尽可能大(减少图中运算数据在不同计算后端之间拷贝的时间损耗),另一方面尽可能利用更快的加速单元(若有些算子在GPU和CPU上同样有实现,优先GPU上的加速实现,但如果仅在CPU上有实现,就只能Fallback到CPU上进行运算,同时为了保证第一条,还可能将几个不兼容算子(连同中间夹杂的少数兼容算子)一同Fallback到CPU)。而假设某个子图被判定为NNAPI兼容,则会被分派到NNAPI的运行时上执行,NNAPI会再次进行分割,按照上文类似的方式将算子分配到合适的硬件HAL上真正执行。
如上段所示,如果我们不考虑硬件算子实现上出现的Bug,那一个模型如果在NPU上运行不佳的原因可能是:
- 由于大部分算子不兼容NPU,因此被调度到CPU上进行运算,此时NPU的加速性能并没有被很好发挥 –> 这种情况下似乎很难有较好的解决办法,幸运的情况下不兼容算子可以使用其他兼容算子进行组合替代(如MatMul其实是由多个FullyConnected进行组合而成),不幸运的情况下就只能放弃或者对模型进行大修,如本人曾经在早期尝试过在GPU上对RNN进行推理,彼时只能因为硬件不支持作罢。
- 大部分算子兼容NPU,但是由于几个频繁出现的算子不兼容NPU,导致子图被分割得很碎片化,异构后端之间数据拷贝的Tradeoff太高,导致推理时延过高。这是我猜想本例中更可能出现的情形,也是有相对简单的解决方案的情形:视模型来尝试替换算子,将少数算子去掉或更换。
- NPU配置问题,查阅资料查找如NPU支持的量化类型不符合或模型是否过大等问题,此外还应当注意,Dynamic Shape Input类型的模型(即输入Shape为(None,X,X)的类型)截止目前可能能不支持。
日志追踪
对于一个黑盒系统,我们首先能做的只能是去查看运行日志。对于TFLite框架,我建议使用自带的Benchmark Tools尝试运行模型测试,首先去除App调用错误的乌龙。传入--use_nnapi=1 --nnapi_allow_fp16=true --nnapi_accelerator_name=google-edgetpu 来允许Benchmark自动量化模型、启用NNAPI并指定NPU运行。在指定NPU后,所有NPU无法执行的算子就不会调度到NNAPI层,而是有TFLite自行分配到CPU上运行,这有利于我们后面进行的Operation Profiling.
Benchmark的结果与一开始类似,NPU的推理平均时延在600ms左右,与我预计的数据(<100ms)相去甚远。好在Benchmark给出了一条很重要的提示:
VERBOSE: Replacing 1965 out of 3220 node(s) with delegate (TfLiteNnapiDelegate) node, yielding 64 partitions for the whole graph.这条提示说明仅有一半左右的算子被分配给了NNAPI,整个模型被切分成了64块子图。根据我个人的经验,一般子图数目在小于20个左右比较合适,大于100个时效果就会变得极差,大量时间被数据拷贝消耗了。然而让我疑惑的是,Transformer模型的大部分算子都是线性,不应当出现这么多NPU无法支持的操作才对,于是我进一步进行分析,传入--enable_op_profiling=true开启对每个算子的详细信息进行输出,输出可能会非常冗长,建议转储到文件分析。
=============== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
FULLY_CONNECTED 1190 405.132 72.506% 72.506% 0.000 1190
TfLiteNnapiDelegate 32 141.459 25.317% 97.822% 0.000 32
Add (ND, F32) 3 4.453 0.797% 98.619% 0.000 13
MEAN 26 3.664 0.656% 99.275% 0.000 26
Squared Difference (NC, F32) 1 2.552 0.457% 99.732% 0.000 13
Copy (NC, X32) 1 1.285 0.230% 99.962% 0.000 7
Convert (NC, QS8, F32) 1 0.161 0.029% 99.991% 0.000 1
GATHER 1 0.041 0.007% 99.998% 0.000 1
Fully Connected (NC, F32) GEMM 1 0.007 0.001% 99.999% 0.000
CAST 1 0.002 0.000% 100.000% 0.000 1
Subtract (ND, F32) 1 0.001 0.000% 100.000% 0.000 1
Multiply (ND, F32) 1 0.001 0.000% 100.000% 0.000 1在OP Profile报告中,被托管到NNAPI上运行的子图会以TfLiteNnapiDelegate的形式显示,无法追踪算子的具体信息,所以我们只需要关心那些被具体列出的算子(这些算子证明无法在NNAPI上运行)即可。但是注意由于我们之前提到的子图尽可能大原则,因此这些列出的算子不一定全都是完全不能运行的算子,我们只关注占比较多的部分即可。令我很诧异的是,不能运行的算子中更多竟然是很基础的FullyConnected层算子,因此这个问题似乎不仅仅是算子不支持那么简单。
从头开始分析,一个TensorFlow中计算首先会被编译为图算子(tf.op),此后在TensorFlow Lite的转化过程中会被转化为TFLite支持的算子(如上文提到的Matmul转为FC)并将结构连同Weighs一同固化在TFLite文件中,再在TFLite Lib运行时转换为NNAPI的抽象OP算子。如果一个看上去很简单的算子无法完成这个流程,那很可能是某个转化过程出了问题,导致最终生成的NNAPI算子被拒绝了。
首先我决定还是利用可视化工具看看TFLite中的算子类型有没有奇怪之处,通用的可视化工具如[Netron]可以显示模型结构,但是不一定可以展示TFLite的私有信息,这里我们使用TFLite自带的可视化工具,如果你已经安装了TF,直接在终端运行:
python -m tensorflow.lite.tools.visualize <TFLite 文件路径> <生成报告HTML文件路径>很遗憾,我这里生成的报告非常庞大(毕竟模型结构比较深)且没啥实用信息。这条路好像不太能走通,我决定还是去翻下子图分派的代码,看看这个OP为什么会被NNAPI拒绝。好在虽然TensorFlow的仓库很庞大,但还算得上有条理。在https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/delegates/nnapi/nnapi_delegate.cc 中找到了较为详细的逻辑。
// Return a function that knows how to translate a node into its operands
// when called. You can use this function to see if a node is supported
// (i.e. if the returned MappingFn is null, then the node is not supported).
bool NNAPIDelegateKernel::Validate(
const TfLiteContext* context, const TfLiteRegistration* registration,
int android_sdk_version, const TfLiteNode* node,
bool is_accelerator_specified, NnapiDelegateVendorPlugin* vendor_plugin,
std::vector<NNAPIValidationFailure>* map_failures) {
...
case kTfLiteBuiltinFullyConnected: {
ExpectMaxOpVersion(version, 5, &val_ctx);
const auto output_type = context->tensors[node->outputs->data[0]].type;
Expect(output_type != kTfLiteInt16,
NNAPIValidationFailureType::kUnsupportedOutputType,
"Unsupported output of type kTfLiteInt16", &val_ctx);
if (android_sdk_version < kMinSdkVersionForNNAPI12) {
Expect(!IsHybridOperator(context, builtin_code, node),
NNAPIValidationFailureType::kUnsupportedHybridOperator,
"Hybrid operators not supported before NNAPI 1.2", &val_ctx);
ExpectIsFloatOrUint8Operator(context, node, &val_ctx);
}
const auto input_type = context->tensors[node->inputs->data[0]].type;
if (android_sdk_version < kMinSdkVersionForNNAPI12 &&
input_type == kTfLiteUInt8) {
ExpectIsRestrictedScalesCompliant(context, node, &val_ctx);
}
auto builtin =
reinterpret_cast<TfLiteFullyConnectedParams*>(node->builtin_data);
if (builtin->keep_num_dims) {
ExpectMinAndroidSdkVersion(android_sdk_version,
kMinSdkVersionForNNAPI13, &val_ctx);
}
} break;
...
}TFLite通过Validate函数来确定某个node能不能在指定后端上运行,如果能运行则返回在后端上的实现Operand(即操作数,负责承载Model中的数据流向或常量,用作Operation的输入与输出),否则返回null.走读下代码,发现代码中依次判断了是否为INT16输出(肯定没有)以及某些特性是否支持(这可能是一个错误点,但是我手上的这台最新款Pixel已经升级到最新版本的Android13 with PixelFeatureDrop,NNAPI也是最新的1.3版本,也应当不会出现问题)。正当我疑惑时,才发现最开始的ExpectMaxOpVersion(version, 5, &val_ctx)调用断言了算子版本,而从上文中的可视化界面可知,生成的FullyConnected算子的Version竟然高达9!
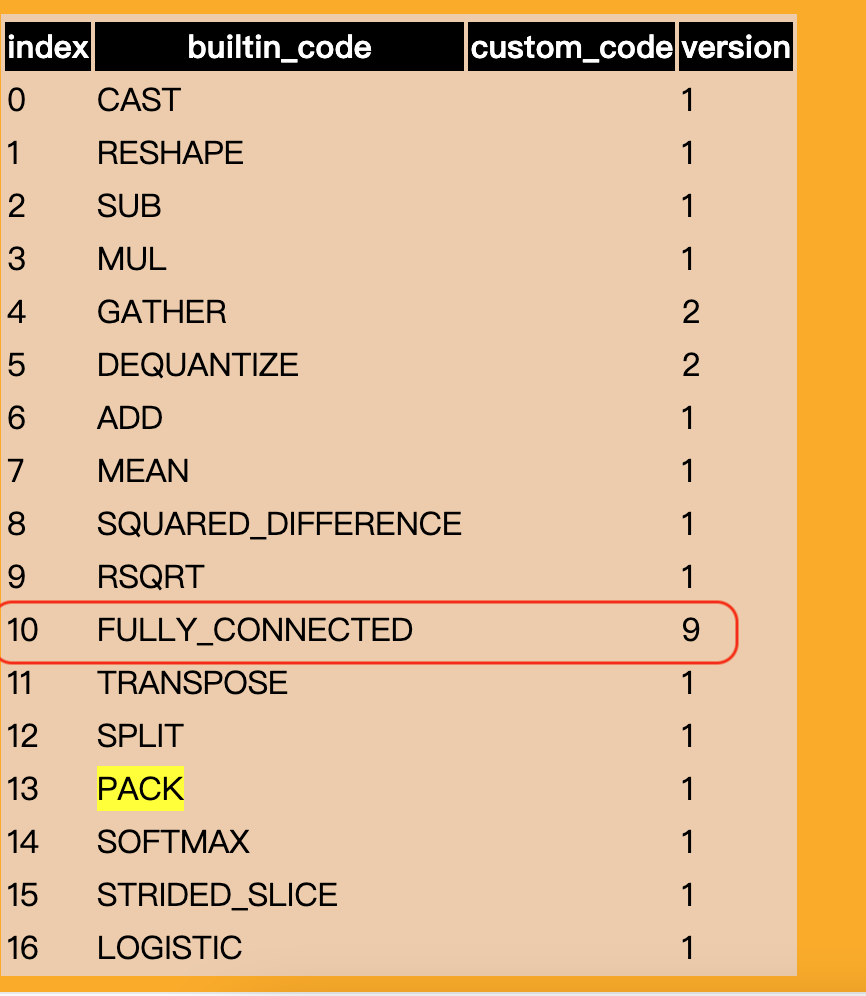
原来,可能是FullyConnected算子引入了什么新特性,而NNAPI Adaptor没有跟进,只是把含有这些新特性的算子全部拒绝了。那么我们只想要去除这些新特性就可以了。再来看看TensorFlowLite转换器的代码,看看是什么导致了版本号狂飙猛进:
// https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/tools/versioning/op_version.cc
int GetBuiltinOperatorVersion(const OpSignature& op_sig) {
switch (op_sig.op) {
...
case BuiltinOperator_FULLY_CONNECTED: {
// +-----------------+--------------------+--------------------------+
// | | Weight::Default | Weight::Shuffled4x16Int8 |
// +-----------------+--------------------+--------------------------+
// | Float | 1 | 2 |
// | Quantized Uint8 | 1 | 2 |
// | Hybrid | 3 | 3 |
// | Quantized Int8 | 4 | 4 |
// +-----------------+--------------------+--------------------------+
// FullyConnected with sparse weight is supported at version 8.
if (op_sig.ext_options.fully_connected.sparse_weight) {
return 8;
}
// Int16 fully fixed point kernel is at version 7.
if (op_sig.inputs.at(0).type == kTfLiteInt16 &&
op_sig.inputs.at(1).type == kTfLiteInt16 &&
op_sig.outputs.at(0).type == kTfLiteInt16) {
return 7;
}
// 2 op_sig.inputs (no bias) use case is supported starting from
// version 6.
if (op_sig.inputs.size() == 2) {
return 6;
}
auto fully_connected_params =
reinterpret_cast<TfLiteFullyConnectedParams*>(op_sig.builtin_data);
TFLITE_DCHECK(fully_connected_params != nullptr);
// `keep_num_dims` is supported at version 5.
if (fully_connected_params->keep_num_dims) {
return 5;
}
// Int8 fully fixed point kernel is at version 4.
if (op_sig.inputs.at(0).type == kTfLiteInt8 &&
op_sig.inputs.at(1).type == kTfLiteInt8 &&
op_sig.outputs.at(0).type == kTfLiteInt8) {
return 4;
}
// If the op has signed int8 and int4 op_sig.inputs and op_sig.outputs,
// its version 7.
if (op_sig.inputs.at(0).type == kTfLiteInt8 &&
op_sig.inputs.at(1).type == kTfLiteInt4 &&
op_sig.outputs.at(0).type == kTfLiteInt8) {
return 10;
}
// If the op is a signed int8 hybrid operation, we need to return
// version 3.
if (op_sig.inputs.at(0).type == kTfLiteFloat32 &&
op_sig.inputs.at(1).type == kTfLiteInt8 &&
op_sig.outputs.at(0).type == kTfLiteFloat32) {
if (fully_connected_params->asymmetric_quantize_inputs) {
// This is to use the updated quantization scheme.
return 9;
}
return 3;
}
// For float and uint8 fixed point kernels, if the weight is
// Shuffled4x16Int8, it is version 2.
if (fully_connected_params->weights_format ==
kTfLiteFullyConnectedWeightsFormatShuffled4x16Int8) {
return 2;
}
// Otherwise (weight is default), the version is 1.
return 1;
}
}看来与模型的算子特性无关,新版本更多是与量化有关系,引入了非对称量化、稀疏weight等特性。然而在转化模型的时候并没有转化量化模型啊?再次以asymmetric_quantize_inputs为关键字在代码库中查询,从MLIR的一条注释得知,当在convertor中指定converter.optimizations = [tf.lite.Optimize.DEFAULT] 时,默认就会包含这个优化策略,并导致OP Version飙升。只能说难绷…
理论上也可以通过魔改MLIR的相关代码关闭这个策略,但是我还是选择了直接关闭了转换优化,效果如下,大部分算子都成功调度到NNAPI上:
VERBOSE: Replacing 3174 out of 3219 node(s) with delegate (TfLiteNnapiDelegate) node, yielding 26 partitions for the whole graph.一朵乌云
然而真正运行时却直接抛出错误: NN API returned error ANEURALNETWORKS_OP_FAILED at line 4735 while completing NNAPI compilation.这下毫无疑问是NNAPI的锅了。查询文档发现 幸好NNAPI留出了一个日志选项,允许我们获取运行时的相关Logs并在logcat中查看:
adb shell setprop debug.nn.vlog all最终发现问题出在设备供应商提供的HAL层,报错信息也十分奇诡:On fd 14, read operation attempted on 40 bytes, but zero bytes affected. (This could be due to reading past EOF). Context: /data/vendor/hal_neuralnetworks_darwinn/NnapiHalSocketSpawnerProcess 这FD打不开算个什么事情!查报错信息未果,HAL的代码肯定也是完全不可见的。在排除了文件损坏之后,我突然想到,在Linux编程中,Hardware Buffer或者MMAP这些东西似乎也经常使用read调用读取,会不会是某个Buffer/内存不足了呢?尝试减小模型推理时的BatchSize,将BatchSize砍半之后成功运行。Latency: 38ms ✅
后记
26个Part还是有点多..能不能再少一点? 仔细看下就会发现 现在影响Part数量的估计是MEAN算子(OP表里说它26个,数字是不是很相近?) MEAN算子也是个常用算子了,为啥会不能跑捏? 这个问题也困惑了我很久,目前发现的结论是 TF的ReduceMean OP单独使用是没有问题的,但是假如在ReduceMean函数中axis参数传入一个数组(一个以上数字) 很可能没办法跑, 而Bert结构中的moments OP更是会出现奇怪的Bug(当axis是1时可以跑,axis>1(比如2)或数组,不能跑).诡异到这种地步,不太想继续往下追了 就这样吧.